로그인 응답시간을 최적화 했던 경험 (서버리스 환경)
서버리스 환경에서 개인프로젝트를 구동하고 있는데 로그인에 걸리는 시간이 너무 길어서 확인을 해 보았다
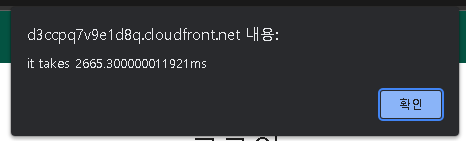
로그인에 2666ms가 걸리는것이 확인된다. 2.6초가 걸린다는 소린데 절대 납득할 수 없는 시간이었다.
로그인 요청시간이 왜 이렇게 오래 걸릴까? 의심가는 이유들을 적어보았는데 대략 아래와 같았다
- 코드가 배포되는 aws의 리전이 미국이다 (물리적인 위치가 멀다)
- 함수가 콜드스타트 될 때 디스크 IO 및 컨테이너 설정 등의 작업으로 인해 시간이 허비된다
- 함수가 콜드스타트 될 때 db서버와 재연결하면서 시간이 허비된다
이렇게 3가지 이유를 염두해두었고 먼저 aws의 리전에 대해 살펴보았다. 본인은 serverless-next라는 배포툴을 사용하고 있었다.
그런데 이 배포툴은 디플로이를 할 때 버지니아 북부(us-east-1)에 디플로이를 수행하고 별도로 리전을 바꿀 수 있는 방법도 없었다.
만일 리전을 서울(ap-northeast-2)로 바꾸면 속도가 향상되지 않을까 하는 기대를 했는데 그건 오해였다.
배포툴의 공식문서를 살펴보니 아래와 같은 내용이 있었다
Serverless Next.js는 리전이라는 개념이 없습니다. serverless-next.js 애플리케이션은 전 세계 모든 CloudFront 엣지 리전에 배포됩니다. 람다는us-east-1리전에만 배포된 것으로 보일 수 있지만 이면에는 모든 다른 리전으로 복제(replication)됩니다.
내용을 정리하면 일단 코드를 버지니아 서버에 배포하고 그 서버리스 함수를 다른 리전으로 복제하기 때문에 리전이 멀어서 생기는 속도이슈는 발생하지 않는다고 한다.
조금 조사해보니 클라이언트의 리전에 맞추어 지리적으로 가장 가까이에 있는 서버리스 함수를 호출하는 아키텍처를 엣지 컴퓨팅이라고 하며 이 엣지컴퓨팅이 적용된 서버리스 함수를 AWS에서는 Lambda@Edge라고 부르는것 같았다
그래서 첫번째 가정은 틀린것으로 확인되었다.
다음으로 콜드스타트에 눈길이 갔다. 먼저 이 콜드스타트가 구체적으로 얼마나 시간을 잡아먹는지 알고 싶었다. 그래서 아무런 기능이 없이 그저 빈 객체를 리턴하는 API 엔드포인트를 만들었다. 아래와 같다
export default EmptyFunction(req, res){
res.json({})
}위의 빈껍대기 함수를 총 2번 호출하였고 각각의 요청에 걸리는 시간을 performance.now()로 측정했다.
2번 호출한 이유는 콜드 상태일 때의 속도와 웜업(warm up) 상태일 때의 응답속도를 각각 얻기 위해서였다.
즉 아래의 2가지 정보를 얻을 수 있다
- 함수가 콜드 상태일 때 응답하는 시간
- 함수가 웜업 상태일 때 응답하는 시간
위의 정보를 이용해서 (콜드 상태일 때 응답하는 시간) - (웜업 상태일 때 응답하는 시간)을 계산하면 순수하게 콜드스타트에만 소모되는 시간을 유추할 수 있다.
5번 수행했을 때 결과는 아래와 같았다
콜드상태 : 553.30ms, 웜업상태 : 99.69ms, 차이 : 453.609ms
콜드상태 : 570.20ms, 웜업상태 : 58.399ms, 차이 : 511.80ms
콜드상태 : 588.19ms, 웜업상태 : 42.79ms, 차이 : 545.40ms
콜드상태 : 549.60ms, 웜업상태 : 52.20ms, 차이 : 497.400ms
콜드상태 : 577ms, 웜업상태 : 54ms, 차이 : 523ms위의 결과를 평균내 보면 콜드스타트에 걸리는 시간은 약 506.24ms 정도로 확인되었다.
상당한 시간이고 이 시간을 없앤다면 속도향상에 상당한 진전이 있을 것이다. 그런데 이 시간을 없앨 수 있을까? 그러기 위해서는 콜드스타트가 무엇인지 이해해야 했다
콜드스타트는 일정시간 동안 요청되지 않은 함수를 메모리에서 해제하고 만일 이후에 함수 요청이 새로 발생하면 그재서야 SSD등의 외부 디스크에서 함수를 메모리에 적재하여 요청을 프로세싱하는 방법이라고 들었다
(출처).
얼마나 오래 사용되지 않은 함수가 콜드 상태로 접어드는지에 대해서는 aws의 공식적인 답변은 없는 듯 했다.
사람들이 말하기를 약 5~7분 가량 사용하지 않으면 콜드 상태로 접어든다고 말하는 사람도 있었고 15분 후에 콜드 상태가 된다는 의견도 있었다.
본인의 생각으로는 메모리 잔여공간이 넉넉하면 15분 가량은 버틸 수 있는 것 같고 메모리 잔여공간이 빠듯하면 5분만 버틸 수 있다는 식으로 추측된다
어찌 되었든 함수가 콜드스타트 되는 현상을 방지하려면 일정시간 이내로 요청이 계속 들어와서 이 함수가 콜드상태로 접어드는 일을 방지해야 한다.
그렇게 하기 위해서는 서비스 이용자가 충분히 많아서 지속적인 요청이 들어오는 경우에는 가능하겠지만 본인의 서비스는 그렇지 않기 때문에 다른 방법이 필요했다.
그래서 aws가 제공하는 프로비저닝된 동시성(Provisioned Concurrency)이라는 서비스를 이용해볼까 생각했다.
이 서비스는 주기적으로 함수에 요청을 날려서 콜드상태로 접어드는것을 방지해주는 서비스라고 한다. 그런데 이 서비스에 문제가 있었다.
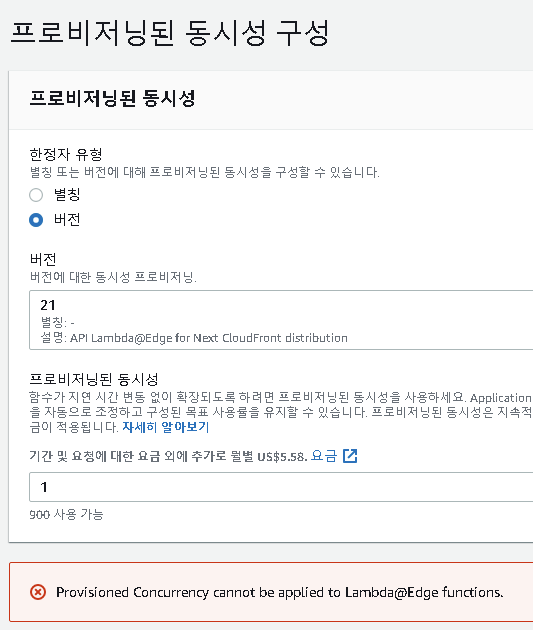
사진의 맨 아래에 Lambda@Edge 함수에는 해당 기능이 적용되지 않는다는 문구가 보인다
이렇게 프로비저닝된 동시성을 사용하겠다는 목표도 좌절되었다.
그래서 좀 단순무식한 방법을 생각해냈다. 랜딩 페이지에 유저가 접속하는 즉시 fetch로 서버리스 함수를 호출하는 코드를 삽입하는 것이었다.
가령 아래와 같다
// coldWakeUp() 만 실행한다
useEffect(_ => {
coldWakeUp()
async function coldWakeUp(){
await fetch('api/login', {
method : 'post',
'content-type' : 'application/json',
body : JSON.stringify({type : 'COLD_WAKE_UP'})
})
}
}, []) // 최초에 1회만 실행된다위의 코드에서 fetch를 수행하면 이 패킷이 전달된 aws서버에서 서버리스 함수가 콜드스타트 된다.
그 이후 req.body.type 을 체크하여 그 값이 COLD_WAKE_UP이라면 db서버와의 커넥트만 수행하고 별도의 로그인 관련 쿼리요청은 수행하지 않는다.
이렇게 랜딩페이지에서 서버리스 함수를 미리 요청해 놓으면 두가지 장점이 있다
-
유저가 로그인 페이지에 접속해서 서버리스 함수를 호출할 때 함수가 이미 웜업(warm up) 상태이므로 콜드스타트에 소모되는 약 506.24ms가 소모되지 않는다
-
콜드스타트를 수행하면서 db 서버와 커넥트가 완료되므로 유저가
로그인 요청을 할 때 db서버와 다시 커넥트할 필요가 없음
과연 그럴까? 그 결과가 아래와 같았다
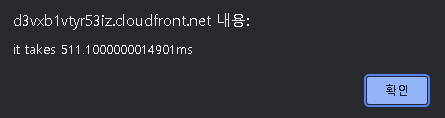
요청에 511ms가 소모되었다. db커넥션에 소모된 시간이 0.005ms인데 사실 db커넥션 유무를 체크만 한 수준이며 db쿼리에 걸리는 시간이 469.60ms로 확인되었다
그 외에 라우팅 등에 소모된 시간은 총 소요시간(511ms) - DB커넥션 체크시간(0.005ms) - DB쿼리 소요시간(469.60ms) = 41.39ms로 약 506.24ms에 육박하는 콜드스타트 시간도 사라진 것이 명백해졌다
그 결과 튜닝전 2665ms였던 요청시간이 511ms이 되어 약 2154ms의 시간 감소가 있었는데 이 정도면 만족스러운 결과였다.
이 쯤에서 그만둘 수도 있었지만 시간을 더 단축하고 싶었다. 그러려면 db에서 데이터를 가져오는 시간을 469.60ms에서 더욱 단축해야 했다.
어떻게 db에서 데이터를 가져오는 시간을 단축할 수 있을까? 대부분의 db는 캐쉬 기능을 이용하면 시간 단축이 가능하다.
대표적으로 레디스(redis)같은 인메모리 캐쉬 솔루션은 SSD등의 스토리지에서 가져온 데이터를 메모리에 캐쉬해 두어서 캐쉬가 히트되는 상황에서는 디스크 IO에 소모되는 레이턴시를 없애준다
그렇게 이것저것 조사하던 중 아래의 글을 발견했다
MongoDB는 가장 최근에 사용한 도큐멘트를 램(RAM)에 캐시합니다 따라서 다음에 이러한 문서를 요청할 때 이미 램에 있으므로 SSD같은 디스크에서 가져올 필요가 없습니다 쿼리하는 도큐먼트가 이미 램에 적재되어 있지 않다면 디스크에서 가져옵니다 램이 가득 차면 새 도큐멘트를 위한 공간을 확보해야 하므로 이전 도큐멘트를 제거한다
— MaBeuLux88 (몽고디비 직원) 출처
이러한 캐싱 전략은 서버리스 함수가 콜드상태일 때와 웜업상태로 나뉘는 것과 상당히 유사한 형태라고 볼 수 있겠다
여담이지만 이런저런 글을 조사해 보던 중 서버리스 함수를 발명한 사람이 db의 인메모리 캐싱 전략에서 영감을 얻지 않았을까 하는 생각이 들었다
각설하고 위의 내용을 로그인 시나리오에 적용해 보면 유저 정보가 들어있는 userInfo 도큐멘트(document)를 DB 쿼리 등으로 미리 참조한 상황에는 userInfo 도큐멘트가 메모리 내에 캐쉬로 남게된다.
따라서 다음번 요청때 userInfo 도큐멘트(document)를 디스크에서 가져오지 않고 메모리에서 캐시형태로 사용할 수 있다
정말 그럴까? 위의 주장이 사실인지 확인해보고 싶었다. 랜딩 페이지에서 유저가 접속하는 즉시 fetch를 수행하여 빠른 콜드스타트를 유도할 때 한가지 프로세스를 더 추가했다
유저 정보가 들어있는 userInfo 도큐멘트를 메모리로 가져오기 위해서 db 쿼리를 수행한 것인데 이러한 db검색은 실제로 존재하는 유저 정보를 검색할 필요는 없으므로 존재하지 않는 적당한 값으로 검색했다. 가령 아래와 같다
await userInfo_model.findOne({userid : "aaa@aaa.aaa"});위의 코드는 서버리스 함수에서 콜드스타트 직후에 실행된다. 이것을 호출하면 userInfo 도큐멘트가 메모리에 캐쉬될 것으로 예상된다.
만일 그렇다면 유저가 로그인 페이지에서 로그인 요청을 할 때 511ms보다 더 빠른 속도의 응답을 받을 수 있을 것인데 그 결과는 아래와 같았다
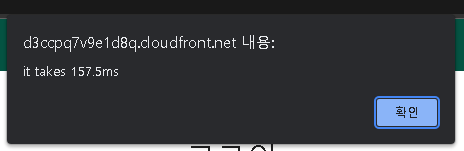
요청에 157.5ms가 소모되었다. 1차 튜닝시에 511ms가 걸렸으므로 도큐멘트의 인메모리 캐싱으로 약 353.5ms의 절감 효과를 보았다
157.5ms는 만족스러웠다. 몇번의 시도결과 107-180ms가량이 걸리는 것으로 확인되었다. 하지만 여기서 시간을 더 줄일 수 있을까? 가능성을 확인해보는 차원에서 지금까지의 아키텍처를 그림으로 확인해보면 아래와 같다
여기서 서버리스 함수를 경유하지 않고 DB서버에서 서버리스 함수를 호출하면 아래와 같다
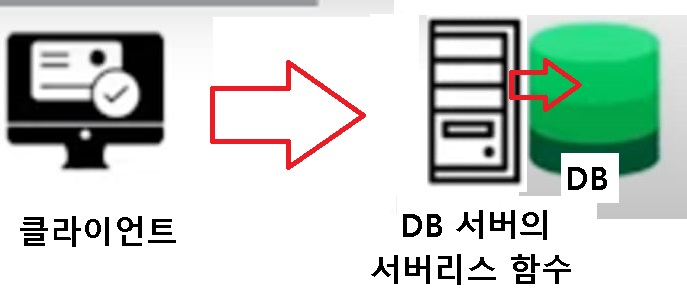
즉 위와 같은 구성이라면 서버리스 함수를 경유하는 시간이 단축된다. 그래서 위와 같은 아키텍처 기반의 db를 찾아보던 도중 몽고디비 렘(MongoDB Realm)이 이와 같은 구성으로 이루어졌다는 사실을 알아냈다. 몽고디비 렘도 몽고디비 아틀라스(MongoDB Atlas)와 마찬가지로 mongodb.com 에서 제공하는 서비스이므로 데이터 마이그레이션 등의 추가적인 작업은 필요하지 않았다
사실 같은 사이트의 게시판 글 읽어오기 컴포넌트는 이미 몽고디비 렘을 사용하고 있던 중이었다. 그래서 글을 받아올 때 걸리는 시간을 벤치마킹 해 본 결과 걸린 시간이 아래와 같았다

음.. 이상했다. 몽고디비 렘의 속도는 대략 97-186ms 사이를 왔다갔다하고 있었다. 이것은 서버리스 함수를 경유하여 DB를 요청하는 것과 거의 차이가 없다. 이 이유는 두가지 중 하나로 추정된다
- 몽고디비 렘의 아키텍처가 안정적으로 최적화가 되지 않았기 때문일 수 있다.
mongodb.com의 모든 서비스는 사실 AWS 인프라 기반에서 작동한다. 따라서몽고디비 렘에서 작동하는 서버리스 함수는 그저aws의 서버리스 함수와 완전히 동일하다. 따라서 서버리스 함수를 경유해서 db서버로 도착하는 것과 몽고디비 렘에서 제공하는 서버리스 함수에서 db서버를 호출하는 작업이 완전히 동일할 수 있다
어쨋든 로그인 페이지에 몽고디비 렘을 적용할 경우 게시판 페이지처럼 97-186ms 사이의 속도를 예상해볼 수 있었다
따라서 최적화에 따른 메리트가 거의 없으므로 이번 최적화는 여기까지로 마무리했다
한계 및 다른 방법론
이번 최적화는 서버리스 함수가 콜드상태로 접어든다는 가정하에 진행되었다. 따라서 함수가 콜드스타트로 좀처럼 접어들지 않는 매우 활성화된 페이지에 적용하기에는 한계가 있다. 활성화된 웹페이지에는 웹브라우저가 제공하는 로컬스토리지(localStorage)를 이용한 캐싱 전략이 유효할 것으로 보인다.
로컬스토리지는 웹브라우저가 제공하는 웹 API인데 도메인 별로 고유의 값을 저장할 수 있다. 이 저장된 값은 비휘발성 데이터이며 웹브라우저를 껏다 키거나 컴퓨터를 껏다 켜도 보존된다. 이 로컬스토리지에 마지막으로 로그인한 유저의 아이디를 저장해놓는다. 그리고 나서 유저가 랜딩 페이지에 다시 접속했을 때 곧바로 마지막으로 로그인한 유저의 아이디 정보를 서버리스 함수로 보낸다. 서버리스 함수는 유저 아이디로 DB에 쿼리문을 날려 유저 정보를 DB에서 미리 가져온다. 이 정보를 캐시로 사용할 수 있다.
만일 해당 사이트에 접속한 유저가 마지막으로 로그인한 유저로 로그인을 요청한다면 미리 가져온 캐쉬가 히트되어 DB를 탐색할 필요도 없이 즉각적인 응답을 제공할 수 있다. 이러한 캐싱 전략은 유저가 기기를 공유하지 않는 상황에 유용하다. 즉 하나의 기기를 한명이 사용하는 상황이라면 하나의 아이디만 사용되는 경우가 대부분이므로 캐시가 히트할 확률은 매우 높다. 반면 PC방처럼 하나의 기기를 여러 명이서 공유하는 환경은 마지막으로 로그인한 유저의 아이디로 로그인을 시도할 확률이 희박하므로 캐시가 히트할 가능성이 낮다
정리 및 결론
로그인 요청의 응답속도를 최적화하는 과정에서 다음의 5가지를 체크했다
- 배포된 리전이 지리적으로 멀어서 느려진 것 같았지만
Lambda@Edge는 리전의 영향을 받지 않으며 클라이언트와 지리적으로 가장 가까운 로케이션으로 자동으로 라우팅되었다. 따라서 리전의 문제는 아니었다 - 콜드스타트에 따른 지연 현상이 있어서
프로비저닝된 동시성(Provisioned Concurrency)이라는 서비스를 이용해볼까 생각했지만Lambda@Edge기반의 함수에는 지원되지 않는 기능이었다 - 유저가 랜딩페이지 접속시에 곧바로 서버리스 함수를 호출하여 빠른 콜드스타트를 유도했다
- 콜드스타트 시에 db와 접속하여 db커넥션에 소모되는 시간을 단축했다
- 콜드스타트 시에 db에서
userInfo 도큐멘트(document)를 검색하여 db의 인메모리 캐싱을 유도했다
그 결과 로그인하기 버튼을 눌렀을 때의 응답속도가 2666ms에서 157.5ms로 약 2508.5ms 감소되었다
향후 연구과제로는 MongoDB의 대안인 Amazon DocumentDB를 사용했을 때 더 나은 속도 개선이 가능한지도 실험해볼만 한것으로 보인다